索引のはなし(上) ~連載「組版夜話」第11話~

※ 2021.1.11改題しました。
 今回は趣向を変えて、 最近の仕事の経験から 「索引づくり」 について書いておきたい。 索引の役目は、 選びだした単語を50音順に並べて、 掲載ページを探せるようにすることである。
今回は趣向を変えて、 最近の仕事の経験から 「索引づくり」 について書いておきたい。 索引の役目は、 選びだした単語を50音順に並べて、 掲載ページを探せるようにすることである。
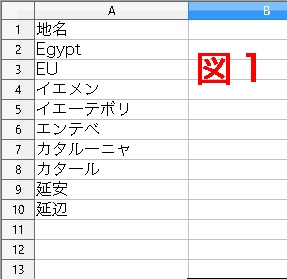
任意の10の外国地名を並べて、 Excelで →データ →並べ替え、 とすると、 右の図1のようになる。 「50音順になってないじゃないか」 「Excelが莫迦なんだ」 と腹を立てる人がいるかもしれない。
コンピュータは人間がつくったものだ。 自然は人間が生まれる前から活動してきたのだから侮れないが、 人間がつくったものは人間が使いこなせる (余談だが、 原子力発電所も人間がつくったものだから、 反省した人間がこれを廃炉にすることは十分に可能である)。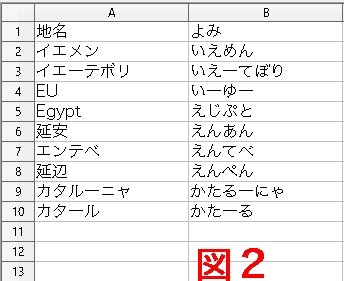
図1のようになってしまうのは、 Excelが悪いのではなく、 使う人間に必要な力、知識が欠如しているためだ。 パソコンのソート (Excelの並べ替え) で昇順というのは、 文字コード順に番号の小さいものから順に並べているのである。 降順はその逆だ。
文字コードは、 異なる用字系をまとめて並べている。 そこでは、 アルファベットが最初で、 仮名はその後、 漢字はさらに後ろという順にしている (ここでは、 シフトJISとかUTF-8とか文字コードの話は省略)。 これが、 エジプト (Egypt) がイエメンより前に並んでしまった理由である。
 いま、 配列したいのは読み順である。 文字コードの番号順ではない。 思い直して、 隣りのBに 「よみ」の列をこしらえて入れてみる。 こうすれば、 仮名という単一の用字系のなかで順番に並んでくれるのではないか、 というわけだ。 再び、 →データ →並べ替え、 で、 優先キーを 「よみ」 列に設定してソートすると、 左上の図2のようになる。
いま、 配列したいのは読み順である。 文字コードの番号順ではない。 思い直して、 隣りのBに 「よみ」の列をこしらえて入れてみる。 こうすれば、 仮名という単一の用字系のなかで順番に並んでくれるのではないか、 というわけだ。 再び、 →データ →並べ替え、 で、 優先キーを 「よみ」 列に設定してソートすると、 左上の図2のようになる。
ん? カタルーニャがカタールより前に来てるのはなぜか。 変だなと思い直して、 文字コード表を見直してみる。 右の図3である。 よくみると、 音引きはずっと後にあるし、 小書きの仮名はふつうの仮名より前に並んでいることに気づく。
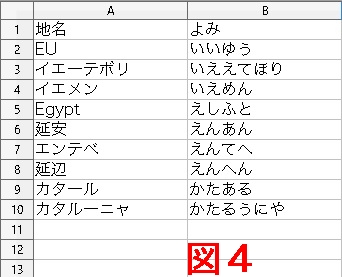 そこで、 音引きは直前の母音に換え、 小書きの仮名はふつううの仮名に換えて、 再ソートしてみる。 結果が、 左の図4である。 こんどはうまくいったようだ。
そこで、 音引きは直前の母音に換え、 小書きの仮名はふつううの仮名に換えて、 再ソートしてみる。 結果が、 左の図4である。 こんどはうまくいったようだ。
ここで、 連載の第2回で、 組版は言語ではなく用字系の決まりごとに則っているという話を思い起こして欲しい。 索引づくりで、 場合によっては、 和字の単語を 「あ~ん」 順に並べ、 別枠で英単語を 「A-Z」順 に並べる場合もあるだろう。
今回やったように、 すべてを単一の、 日本語読みの順に並べる場合は、 単一の用字系、 しかも濁音や半濁音は清音に、 小書きの仮名はふつうの仮名に、 音引きは直前の母音に、それぞれ換えて整える準備が必要なのである(読みの順といっても、 電話帳式とかいろいろ種類があるが、ここでは省略)。
〔この項、 次回につづく〕
連載「組版夜話」もくじ
- 第1話 千遍一律なルールという思い込みの罠 2020.7.11
- 第2話 和文組版は“日本語の組版”ではない!? 2020.7.30
- 第3話 小ワザをいくら積み上げても砂上の楼閣 2020.8.11
- 第4話 ベタ組みは和文組版の基礎リズムである 2020.8.30
- 第5話 「原稿どおり」をめぐる混乱 解決の切り札は何か 2020.9.11
- 第6話 ルビ組版を考える(上) 2020.9.30
- 第7話 ルビ組版を考える(下) 2020.10.11
- 第8話 用字系の個々の歴史を無視して斜体を真似る勘違いと思い上がり! 2020.10.30
- 第9話 千鳥足の傍点はどこから来たのか 2020.11.11
- 第10話 段落の始めの字下げ(空白)は文字なのか、空きなのか? 2020.11.30
- 第11話 索引のはなし(上) 2020.12.11
- 第12話 索引のはなし(中) 2020.12.30
- 第13話 索引のはなし(下) 2021.1.11
- 第14話 行間と行送り 2021.1.31
- 第15話 続・行間と行送り 2021.2.11
- 第16話 続々・行間と行送り 2021.2.11
- 第17話 字送りと行長 2021.3.12
- 第18話 URLという難問 2021.4.2
- 第19話 続・URLという難問 2021.4.11
- 第20話 組版の品質を上げるひとつの点検方法 2021.4.29
- 第21話 行末の句読点ぶら下げは,はたして調整を減らす「標準」なのか 2021.5.17

1954年、大阪生まれ。新聞好きの少年だったが、中国の文化大革命での壁新聞の力に感銘を受け、以来、活版―電算写植―DTPと組版一筋に歩んできた。
1992-1993 みえ吉友の会世話人、1996-1998 日本語の文字と組版を考える会世話人、1996-1999 日本規格協会電子文書処理システム標準化調査研究委員会WG2委員。現在、神戸芸術工科大学で組版講義を担当。
汀線社WEB https://teisensha.jimdofree.com/
KDU組版講義 http://www.teisensha.com/KDU/
繙蟠録 http://www.teisensha.com/han/hanhanroku.htm
日本中のクリエイターを応援するメディアクリエイターズステーションをフォロー!




